JSM AI 에이전트 만들기(1편) : Confluence, '똑똑한 AI 비서'로 만드는 첫걸음
"분명 아는 내용인데..." 검색창 앞에서 한숨 쉬는 당신에게
퇴근 시간 10분 전. 길었던 오늘 하루의 업무를 드디어 마무리하고, 가벼워진 마음에 슬쩍 미소가 지어지던 바로 그 순간. 화면 오른쪽 아래, 너무나도 익숙한 알림 팝업이 반짝입니다.
어제 오후에만 세 번을 답변했던 바로 그 질문. 팀 Confluence 스페이스에 그림까지 곁들여 정말 찾기 쉽게 정리해 둔 바로 그 내용. 순간 스쳐 가는 감정은 단순히 '귀찮음'이 아닐 겁니다.
내 전문성과 소중한 시간을 더 가치 있고 창의적인 곳에 쓰고 싶은 마음, 단순 반복 업무의 끝없는 굴레에서 벗어나고 싶은 작은 소망 같은 것들이겠죠. 😮💨
이건 비단 저만의 이야기는 아닐 거예요. 아마 이 글을 읽고 계신 많은 분들의 오늘 혹은 어제의 모습일지도 모릅니다.
만약, 이런 우리들의 답답한 마음을 알아주는 똑똑한 AI 비서가 24시간 대신 답변해준다면 어떨까요?
사용자는 기다릴 필요 없이 바로 정확한 정보를 얻어서 좋고, 우리는 반복 업무의 굴레에서 벗어나 더 중요한 문제 해결에 집중할 수 있어서 좋고요. ✨
오늘은 바로 그 상상을 현실로 만드는, 우리 팀만의 든든한 AI 비서를 만드는 모든 여정의 첫걸음을 떼려고 해요. 코딩을 몰라도 괜찮아요. 차근차근, 저만 따라오시면 여러분의 JSM에도 아주 멋진 변화가 시작될 거예요!
(핵심 원리) AI는 어떻게 '의미'를 이해할까요?
본격적인 만들기에 앞서, 우리가 만들 AI 비서가 왜 지금의 검색 기능보다 훨씬 똑똑할 수 있는지, 그 비밀을 살짝 알려드릴게요.
도서관의 '검색 컴퓨터'처럼, 책 제목이나 저자 이름을 정확하게 입력해야만 원하는 책을 찾아줘요. 조금만 단어가 달라도 "검색 결과 없음"이라는 차가운 답변만 돌아옵니다. 😥
다정한 '전문 사서님'처럼, "마법을 쓰는 어린 소년이 나오는 판타지 소설을 찾고 있어요"라고 두루뭉술하게 말해도, "아, '해리 포터'를 찾으시는군요?"하고 찰떡같이 알아듣죠. 바로 단어의 '의미'와 '문맥'을 이해하기 때문이에요.
그렇다면 AI는 어떻게 '의미'를 이해할 수 있을까요? 바로 '벡터 임베딩'이라는 마법 덕분이랍니다. 🪄
'벡터 임베딩'은 아주 간단히 말해, 글자를 AI가 이해할 수 있는 '의미가 담긴 좌표'로 번역하는 기술이에요. 예를 들어 '기쁨'과 '행복'이라는 단어는 이 좌표 지도 위에서 아주 가까운 곳에 위치하고, '기쁨'과 '슬픔'은 서로 반대편 멀리에, '기쁨'과 '책상'은 전혀 상관없는 곳에 자리를 잡게 되죠.
그리고 이 '의미 지도'를 보관하는 특별한 서재가 바로 '벡터 데이터베이스(DB)'랍니다. AI는 이 특별한 서재 안에서, 단어가 아닌 '의미'를 기준으로 우리가 원하는 정보를 순식간에 찾아낼 수 있어요.
이제, 이 놀라운 원리를 우리 JSM에 적용해볼까요?
(n8n 실전) Confluence 문서를 'AI의 기억 조각'으로 만드는 과정 엿보기
자, 이제 n8n 워크플로우 캔버스를 펼치고, Confluence 문서 하나가 'AI의 기억 조각'으로 재탄생하는 흥미진진한 여정을 왼쪽 끝에서부터 오른쪽으로 함께 따라가 봐요. 코딩 한 줄 없이, 블록을 연결하는 것만으로 이 모든 일이 가능하답니다!
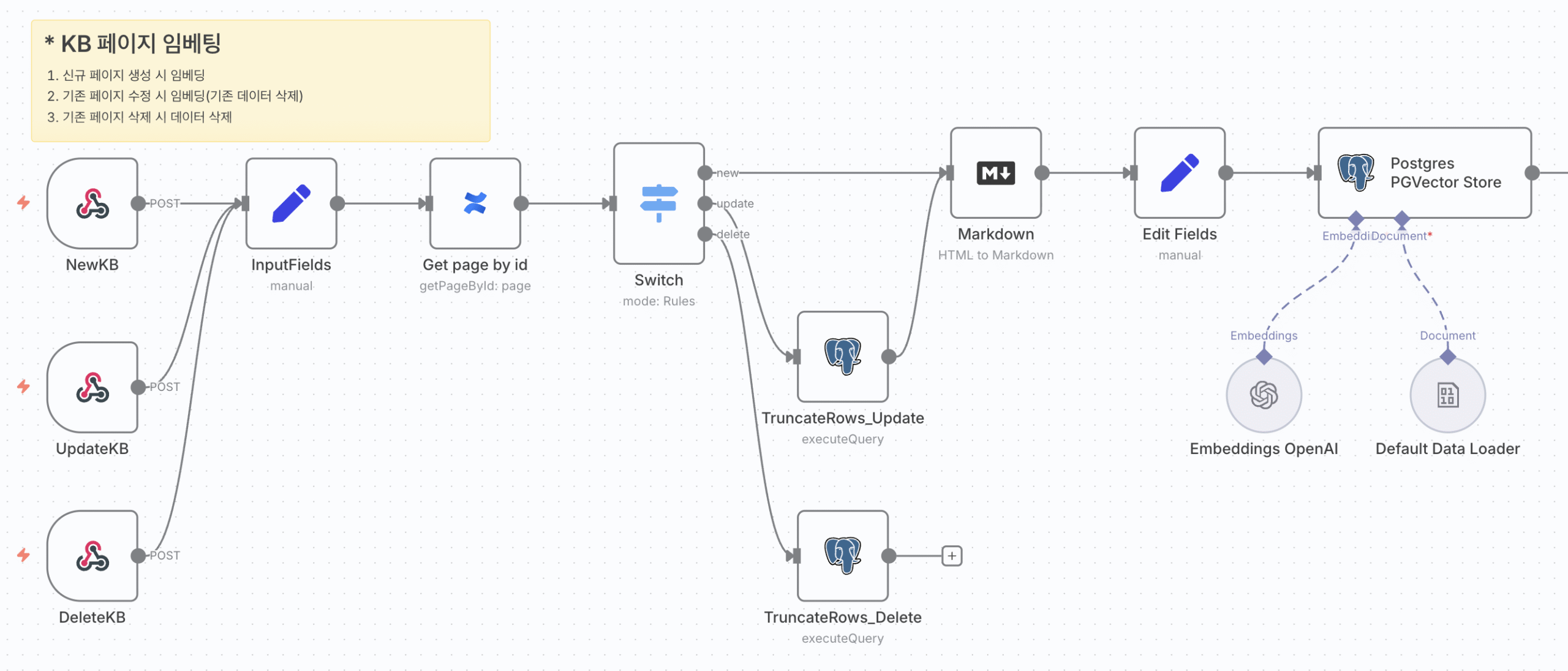
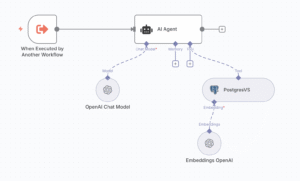
KB-KBEmbeddings 워크플로우 전체 구조
여정의 시작: Confluence의 작은 신호 (Webhook 노드)
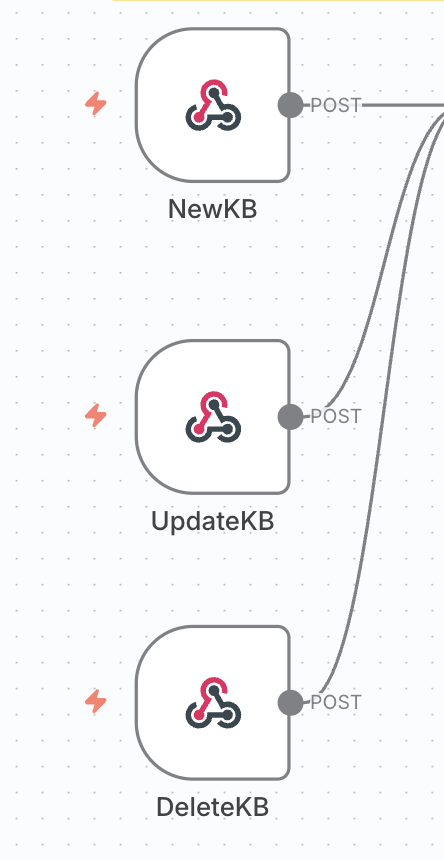
NewKB, UpdateKB, DeleteKB 웹훅 노드들
모든 여정은 워크플로우의 가장 왼쪽, Confluence에서 울리는 작은 신호에서 시작돼요. 문서가 새로 만들어지거나(NewKB), 수정되거나(UpdateKB), 혹은 삭제될 때(DeleteKB), Webhook 노드가 가장 먼저 "여기 변화가 생겼어요!" 하고 똑똑하게 신호를 포착하죠. 우리 여정의 출발을 알리는 '출발 총성' 같은 역할이에요.
정보 수집: 어떤 문서일까? (Get page by id 노드)
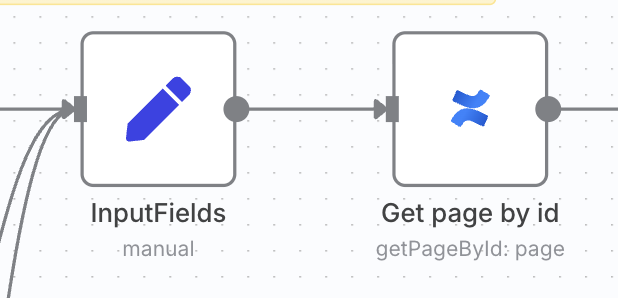
Confluence에서 페이지 정보를 가져오는 Get page by id 노드
신호를 받으면, 우리는 어떤 문서에 변화가 생겼는지 알아야겠죠? Webhook이 전달해준 문서의 고유 ID를 가지고, Get page by id 노드가 Confluence로 달려가 문서의 제목, 내용, 주소(URL) 등 모든 정보를 싹 가져옵니다. 본격적인 임무를 위한 정보 수집 단계죠.
갈림길: 신규, 수정, 아니면 삭제? (Switch 노드)
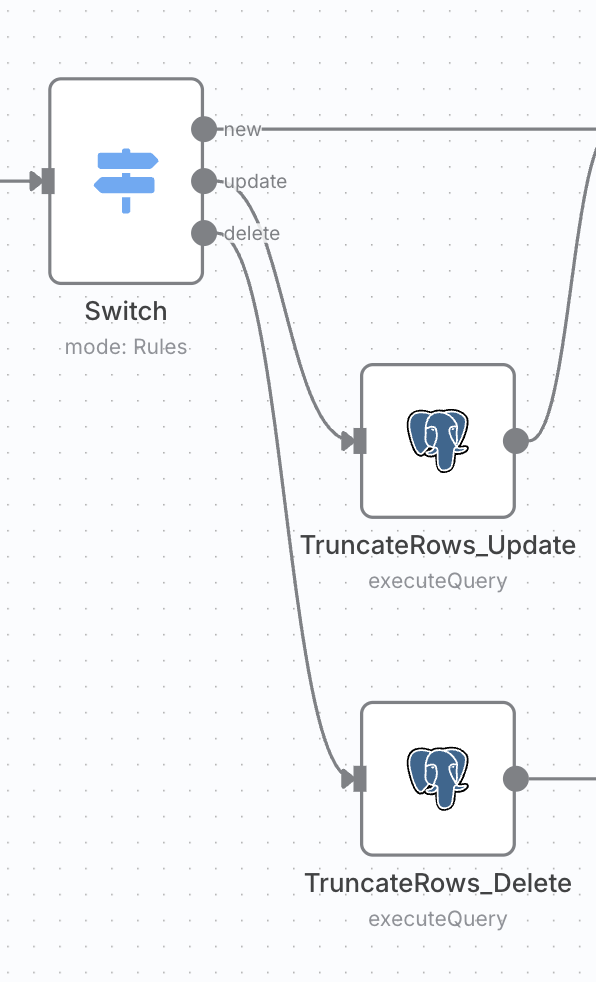
작업 유형에 따라 분기하는 Switch 노드
정보 수집을 마친 데이터는 이제 갈림길에 섭니다. Switch 노드가 "이 신호는 '새 문서'에 대한 건가요, '수정'인가요, 아니면 '삭제'인가요?" 하고 교통정리를 해주죠.
- '삭제' 신호라면? 데이터는 아래쪽 길로 빠져, AI의 기억 서재에서 해당 내용을 지우는 간단한 임무를 수행하고 여정을 마칩니다.
- '수정' 신호라면? 역시 아래쪽 길로 먼저 빠져 옛날 기억을 깨끗이 지운 뒤, '새 문서'와 마찬가지로 오른쪽의 메인 도로로 다시 합류해 새로운 기억을 저장할 준비를 해요.
- '새 문서' 신호라면? 망설임 없이 오른쪽의 메인 도로를 따라 쭉 나아갑니다!
메인 도로: AI의 기억을 만드는 핵심 과정 (오른쪽으로!)
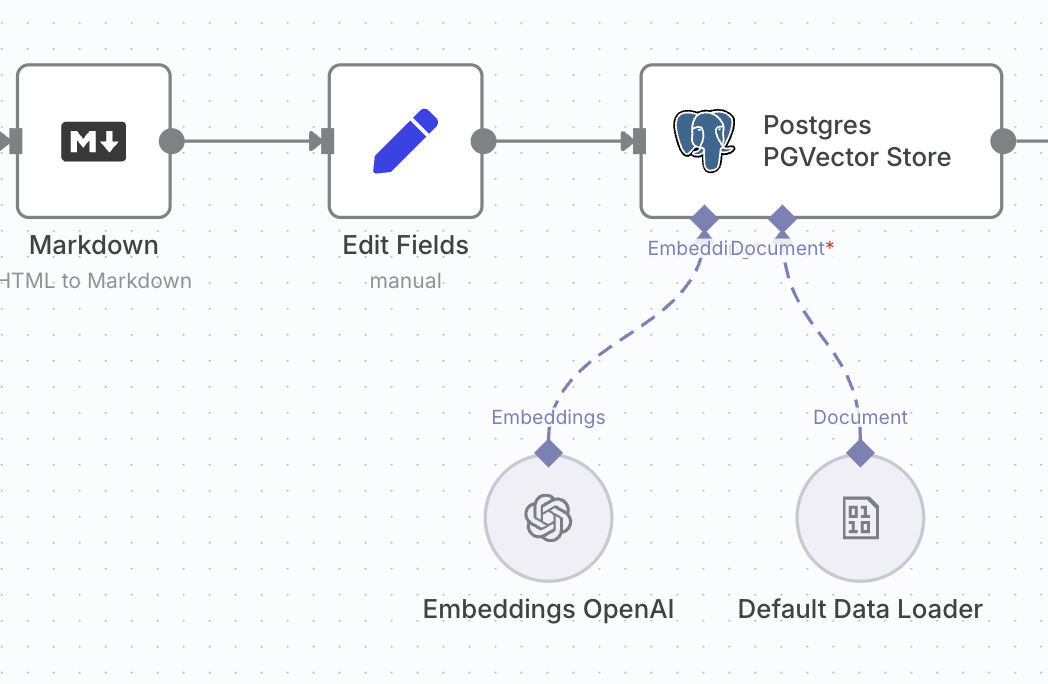
문서를 AI가 이해할 수 있는 벡터로 변환하는 임베딩 과정
이제부터가 진짜 하이라이트예요. 오른쪽으로 나아가는 데이터는 다음과 같은 마법 같은 변신을 거칩니다.
이로써 Confluence 문서 하나의 기나긴 여정이 끝나고, AI 비서의 든든한 지식 하나가 더 쌓이게 되는 것이랍니다.
이제 AI가 우리 팀의 언어를 이해할 준비를 마쳤습니다
어떠셨나요? 오늘 우리는 Confluence에 흩어져 있던 우리 팀의 소중한 지식들을, AI가 '의미'로 이해하고 기억할 수 있는 체계적인 '뇌'로 만들어 주었습니다. 단순한 문서 더미가, 이제 정말로 살아 숨 쉬는 '지식 베이스'가 되는 첫걸음을 뗀 것이죠.
이렇게 튼튼하게 만들어진 AI의 뇌를 활용해서, 이제 어떻게 사용자의 질문에 정확하고 신뢰도 높은 답변을 생성하게 할 수 있을까요?