JSM AI 에이전트 만들기(2편) : AI가 '사실'만 말하게 하는 똑똑한 기술, RAG
"AI가 너무 그럴듯하게 거짓말을 하던데요?"
혹시 AI와 대화하다가, 너무나도 그럴듯한 거짓말에 깜빡 속을 뻔한 경험 없으신가요?
저는 얼마 전, AI에게 우리 회사 내부 규정에 대해 물어봤다가 아찔했던 경험이 있어요. AI는 정말 자신감 넘치는 목소리로 규정 번호까지 대며 상세하게 답변해 줬죠. 하지만 뭔가 쎄한 기분에 원본 문서를 찾아보니, 가장 중요한 핵심 내용이 교묘하게 틀려있더라고요. 만약 제가 그 답변을 그대로 믿고 동료에게 전달했다면, 정말 큰일 날 뻔했습니다.
이처럼 AI가 잘못된 정보를 사실인 것처럼 만들어내는 현상을 '환각(Hallucination)'이라고 불러요.
일상적인 대화에서는 그저 작은 해프닝으로 끝날 수 있지만, 우리 회사의 중요한 정보를 다루는 JSM AI 비서에게 '신뢰성'은 무엇보다 중요한 덕목이겠죠? 우리 비서는 절대 부정확한 답변을 해서는 안 되니까요.
그래서 오늘은 우리 AI 비서의 자유로운 상상력은 잠시 넣어두고, 오직 우리가 1편에서 만들어준 'Confluence 지식'이라는 검증된 사실만을 말하게 하는 아주 똑똑하고 중요한 기술, 'RAG'에 대해 알아보려고 해요.
(핵심 원리) RAG, AI에게 '오픈북'을 선물하는 기술
RAG는 'Retrieval-Augmented Generation', 우리말로는 '검색 증강 생성'이라는 조금 어려운 이름을 가졌어요. 하지만 원리는 아주 간단하답니다. 바로 AI에게 '오픈북 테스트'를 보게 하는 것과 같아요!
우리가 시험을 볼 때, 머릿속 기억에만 의존해서 답을 쓰는 '클로즈드북 테스트'와 책을 마음껏 펼쳐놓고 답을 찾는 '오픈북 테스트'는 전혀 다르죠?
AI는 마치 '클로즈드북 테스트'처럼, 인터넷 세상의 방대한 지식을 바탕으로 상상력을 더해 답변을 만들어내요. 그러다 보니 가끔씩 사실과 다른 내용을 지어내기도 하죠.
AI는 '오픈북 테스트'처럼, 우리가 "이것만 봐!" 하고 정해준 'Confluence 참고서'를 펼쳐놓고, 그 안에서만 정답을 찾아 답변합니다. 절대 참고서에 없는 내용은 말하지 않죠.
이 안전한 '오픈북 테스트'는 다음과 같은 3단계로 이루어져요.
- 검색 (Retrieval): 먼저, 사용자의 질문과 가장 관련 있는 페이지를 'Confluence 참고서'에서 부지런히 찾아냅니다.
- 증강 (Augmented): 그리고 원본 질문지에, 방금 찾은 참고 페이지 내용을 스테이플러로 '찰칵' 붙여주죠.
- 생성 (Generation): 마지막으로 AI에게 "자, 여기 질문지와 참고 내용이야. 이 안에서만 보고 답을 작성해줘!" 라고 지시하는 거예요.
어때요, 정말 안전하고 확실한 방법이죠?
(n8n 실전) '사실 검색' 워크플로우의 여정 (KB-SemanticSearch.json)
자, 이제 이 똑똑한 RAG 원리가 n8n 워크플로우 안에서 어떻게 실제로 움직이는지, 그 여정을 함께 따라가 봐요.
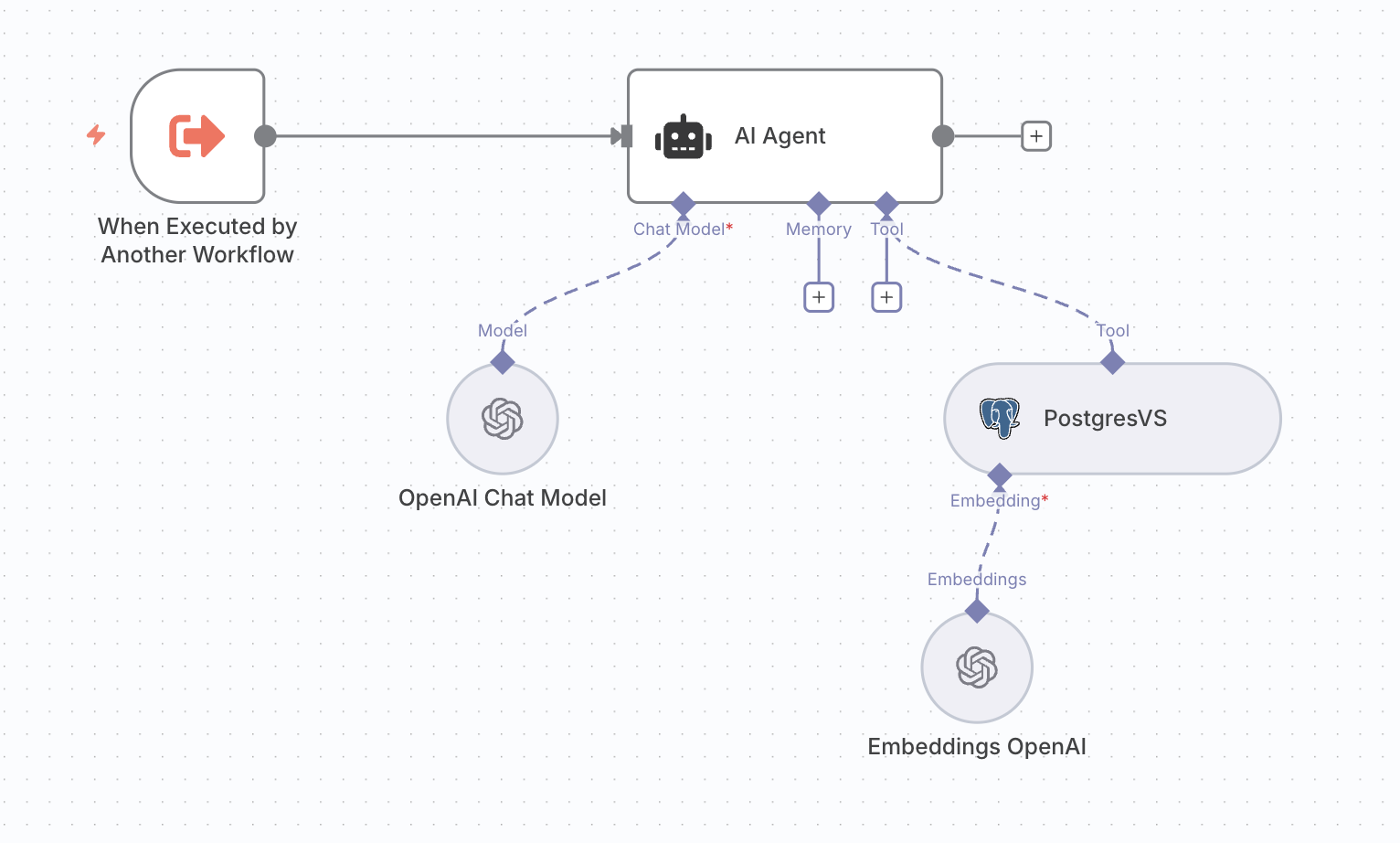
KB-SemanticSearch 워크플로우 전체 구조
임무 시작! 질문을 전달받다 (Execute Workflow Trigger 노드)
다른 워크플로우에서 호출을 받는 Execute Workflow Trigger
이 워크플로우는 스스로 시작하지 않아요. 나중에 만들 최종 챗봇(3편)으로부터 "이 내용에 대해 자세히 찾아봐 줘!" 라는 질문(키워드)을 전달받아야만 임무가 시작된답니다. Execute Workflow Trigger 노드가 바로 그 임무를 전달받는 출발점이죠.
작전 지휘! 똑똑한 지휘자의 등장 (AI Agent 노드)
전체 검색 과정을 총괄하는 AI Agent
임무를 전달받으면, 이 워크플로우의 총괄 지휘자인 AI Agent 노드가 깨어납니다. 이 친구가 바로 '사실 검색' 임무의 두뇌 역할을 하죠.
AI Agent는 전달받은 질문을 분석하고, 자신의 작전 계획서(시스템 프롬프트)에 따라 "음, 이 임무를 해결하려면 나의 전문 검색팀을 출동시켜야겠군!" 하고 스스로 판단을 내립니다.
자료 조사! 전문 검색팀의 활약 (PostgresVS 도구)
벡터 데이터베이스에서 시맨틱 검색을 수행하는 PostgresVS
지휘자의 명령이 떨어지면, 최고의 정예 요원으로 구성된 전문 검색팀, PostgresVS 도구가 즉시 출동합니다!
이 검색팀은 1편에서 우리가 열심히 만들어 둔 AI의 기억 서재(벡터 DB)로 달려가요. 그리고 단순 키워드 검색이 아닌, 질문의 '의미'를 이해하는 '시맨틱 검색' 기술을 사용해, 사용자의 의도와 가장 정확하게 일치하는 '사실' 문서들을 바람처럼 찾아냅니다.
최종 보고! 결과물을 정리하여 전달하기
전문 검색팀이 찾아온 정확한 '사실' 문서들을 바탕으로, 지휘자(AI Agent)는 최종 보고서를 작성합니다. 검색된 내용을 빠짐없이, 왜곡 없이 담아 "임무 결과는 이렇습니다" 하고 다시 처음 임무를 지시했던 메인 워크플로우로 전달해주죠.
이로써 '사실 검색'이라는 아주 중요한 임무가 완벽하게 마무리됩니다.
신뢰할 수 있는 우리 팀 AI 전문가의 탄생
오늘 우리는 AI에게 아주 중요한 '정직'과 '신뢰'를 가르쳤습니다.
1편에서 똑똑한 '뇌'를 만들어 주었다면, 2편에서는 그 뇌를 올바르게 사용하는 '대화 원칙'을 세워준 것이죠. 이제 우리 AI 비서는 창의적인 상상가가 아닌, 오직 Confluence에 담긴 사실만을 말하는, 우리가 100% 믿고 의지할 수 있는 전문가로 거듭났습니다.
이제 모든 준비는 정말 끝났습니다. 이렇게 똑똑하고 정직하기까지 한 우리 AI 전문가를, 드디어 실제 JSM 채팅창에 연결해 동료들과 만나게 해줄 시간이에요.